分布式系统中CAP原理
本文共 885 字,大约阅读时间需要 2 分钟。
分布式系统CAP原理
分布式系统发开虽然有点很多但是并不是完美的,CAP原理就是其中的体现之一。
CAP原理:指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partitontolerance(分区容忍性),三者不可得兼。一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。简单说就是所有节点在同一时刻的数据完全一致,这就意味着节点越多数据同步的时候约消耗时间。
比如说分布式数据存储,多台设备需要存储同样的数据,这样一来一旦数据更变那么其他数据库肯定要同步数据,这就意味着我设备越多,我同步的速率也就会越慢,消耗的时长就越多。可用性(A):负载过大后,集群整体是够还能响应用户正常的读写请求。简单说就是项目不管怎么滴,我系统对于用户请求的响应时间肯定在能接受的范围内的,用户体验不能没有啊。
分区容忍性(P):分区容忍性,就是高可用性,一个节点崩了不会影响其他节点。简单说就是我服务器节点崩了几个没事,只要我有正常的服务器就行了,这样就是说我节点越多就越好了。
CAP不得兼得原理
CAP理论就是说在一个分布式系统中,最多只能实现上面的两点。那我们来分析下。
第一: 拥有AP的时候为什么C不能实现?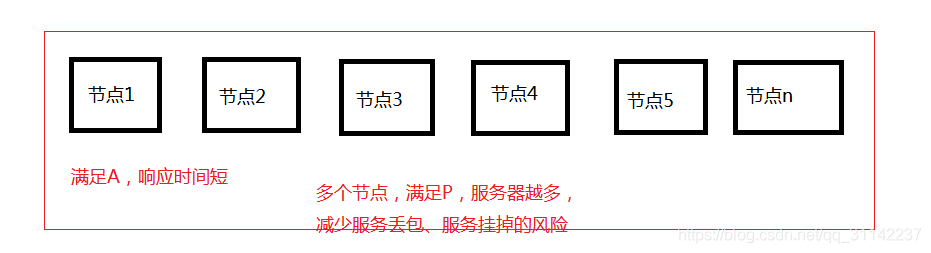 根据上图我们来分析,比如我现在拥有10000个节点,现在要做数据备份,要将10000台设备(p满足了)上都备份上同样的数据,保持数据的一致性(C),我们想象10000台设备数据的同步必然是需要消耗时间,那么我们就没办法实现A,所以要想实现AP那,就不可能保证数据的一致性的。 第二 拥有CP不能为什么不能实现A? 也很好理解,10000台设备,我要保持数据一致性,我就没法保证请求相应时间很短了是吧。 第三 拥有CA为什么不能实现P? 同样的我想要保证数据的一致性,也就是数据的复制,又要保证在合理的请求相应时间内,那么我机器设备不可能很多了,这样就不能满足P了。
根据上图我们来分析,比如我现在拥有10000个节点,现在要做数据备份,要将10000台设备(p满足了)上都备份上同样的数据,保持数据的一致性(C),我们想象10000台设备数据的同步必然是需要消耗时间,那么我们就没办法实现A,所以要想实现AP那,就不可能保证数据的一致性的。 第二 拥有CP不能为什么不能实现A? 也很好理解,10000台设备,我要保持数据一致性,我就没法保证请求相应时间很短了是吧。 第三 拥有CA为什么不能实现P? 同样的我想要保证数据的一致性,也就是数据的复制,又要保证在合理的请求相应时间内,那么我机器设备不可能很多了,这样就不能满足P了。 依据现在的网络硬件肯定会出现延迟对包的情况,设置个别服务器崩溃,起码得保证系统正常的运行,所以**分区容忍性(P)**是不能缺少的。
转载地址:http://vnhof.baihongyu.com/
你可能感兴趣的文章
个人学习方法分享
查看>>
时隔多年。。终于有一款云原生消息系统出仕了!
查看>>
[译]数据包在 Kubernetes 中的一生(1)
查看>>
[译]数据包在 Kubernetes 中的一生(2)
查看>>
[译]数据包在 Kubernetes 中的一生(3)
查看>>
从源头解决 Service Mesh 问题最彻底!
查看>>
一次“不负责任”的 K8s 网络故障排查经验分享
查看>>
一次有趣的 Docker 网络问题排查经历
查看>>
KubeSphere Meetup 北京站火热报名中 | 搭载 CIC 2021 云计算峰会
查看>>
深入理解 Linux Cgroup 系列(一):基本概念
查看>>
深入理解 Linux Cgroup 系列(二):玩转 CPU
查看>>
云原生周报第 1 期 | 2019-06-24~2019-06-28
查看>>
Kubernetes Pod 驱逐详解
查看>>
kubectl 创建 Pod 背后到底发生了什么?
查看>>
[译] Kubernetes 儿童插图指南
查看>>
云原生周报第 2 期 | 2019-07-01~2019-07-05
查看>>
kubectl 创建 Pod 背后到底发生了什么?
查看>>
Kube-scheduler 源码分析(二):调度程序启动前逻辑
查看>>
kubernetes 1.15 有哪些让人眼前一亮的新特性?
查看>>
云原生周报:第 3 期
查看>>